1. 画像圧縮のしくみ
ここでは、画像圧縮技術の主要な部分をとりあげ、しくみを説明する。
データの冗長性を除去して情報を圧縮した場合に、情報の欠落なしに符号量(bit数)だけを減らせる限界が“本来の情報量”であると言える。この情報量を“エントロピー”、データの冗長性を省くための符号化を“エントロピー符号化”と呼ぶ。また、欠落がない圧縮を可逆圧縮といい、元の完全なデータには復元できない圧縮を非可逆圧縮と呼ぶ。
1章では、簡単に画像圧縮のしくみについて説明するが、1.1 では汎用的な符号化、1.2 では静止画像圧縮符号化について述べる。そして、1.3 では動画の圧縮の仕組みについて述べる。
1.1 エントロピー符号化
ここで述べるランレングス符号化、ハフマン符号化は、画像以外の圧縮時にも使える可逆圧縮の符号化である。また、これらはエントロピー符号化に分類される。
(a) ランレングス符号化
ランレングス符号化では同じ文字がいくつか連続している場合に、それらを一つの文字と、文字の個数で表わす情報に変換する。以下、例を示す。
AAAAAAABBB という文字データは、A7B3というデータに圧縮される。実際には、文字データと文字数の区別を付けるために、フラグを用いる。
圧縮フラグを $ とした場合、
AAAAABCDDDD は、$A5BC$D4と表わせる。
このように、単純な符号化であるが、入力データの値が連続する場合には、特に有効な圧縮方式である。また、フラグを利用する事によって、あまり連続しないデータの圧縮時に、元データよりデータ量が大きくなってしまう事を防いでいる。具体的にいうと、AA(2文字)というデータがあった場合に、$A2(3文字)とせずに、そのままAAとしていると思われる。
(b)ハフマン符号化
ハフマン符号化とは、出現頻度の高いデータに少ない桁数の符号(ビット)を割り当てて、全体の情報量の削減を目的とした符号化の一つである。
次にハフマン符号化のアルゴリズムについて述べる。
1) 入力ファイルに存在する各データの出現頻度から統計データを作成し、出現頻度順にならべる。
2) 最も小さい出現頻度を持つ事象2個の確率の和を求める。
3) 前記2個の事象の確率頻度を足し、それをされに1個の事象とみなす。
4) 前記の 1〜3 までを繰り返す。
5) 経路を逆に辿り、確率が大きい方に0を割り当て小さいほうに1を割り当てる。
上記のアルゴリズムを使用したハフマン符号木について、図4.1-bで示す。
“adcaeabaacb”というデータを例として用いる。
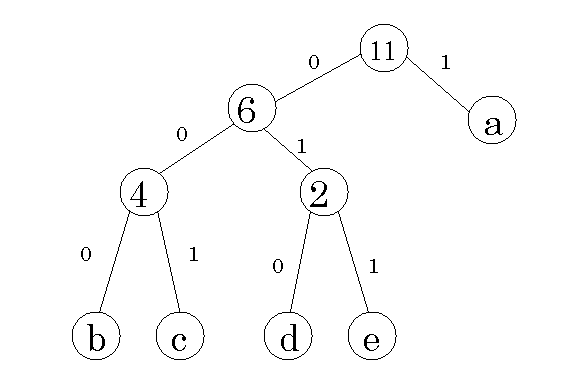
図1.1-a サンプルデータのハフマン符号木表現
|
文字 |
出現頻度 |
2進符号 |
|
a |
5 |
1 |
|
b |
2 |
000 |
|
c |
2 |
001 |
|
d |
1 |
010 |
|
e |
1 |
011 |
表1.1-b ハフマン符号化を適用した場合の表
ハフマン圧縮は、不均一に現れる入力データに対して有効である。デメリットは、出現頻度を調べる為、入力データを二度読まなければならない。そのため、符号化の実行速度を遅くし、CPUのオーバヘッドにつながると考える。
1.2 静止画像の符号化
(a)DPCM符号化
一般的な画像は、色や明るさが、急激に変化するのは輪郭部だけで、となりあった大部分の画素は似通った成分になっている事が多い。それを更に進めて、隣接の画素値から符号化する画素値を予測し、予測値と実際の画素値との誤差を符号化するというDPCM符号化が考えられた。つまり、誤差が0という“一定の値”に近傍できるなら符号化量削減効果も大きくなるという観点から考えられた物である。予測値のとり方は、図で表わした記号を用いて説明する。
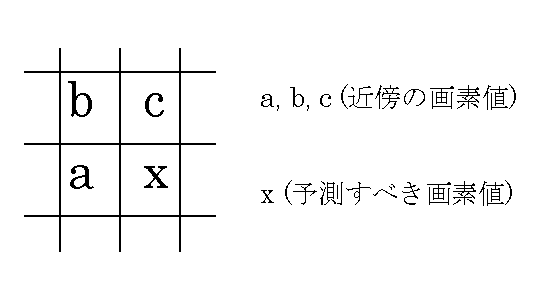
図1.2-a 予測値を求める際の概念図
予測値=(x−a)−(c−b)と表わす事ができる。そして、静止画像を画素に分割し、最左列画素と最上行画素を除き残りの全ての画素について予測値表を作り、実際の画像の誤差を符号化する。予測値とは、それぞれの画素における上の画素と左の画素との差分である事が図1.2-a 及び予測値の計算式からも分かるだろう。
(b) DCT (離散コサイン変換:Discrete Cosine Transform)
ここで述べるDCTという変換符号化は、JPEGやMPEG で利用される符号化であり、重要な役割を担う。また、DCTとは、デジタル信号で表わせた静止画像をブロックに分けて、その中の値を周波数成分に変換する。後述の周波数分解方式のイメージを次ページの図1.2-bで示す。
まず、画像の周波数表現について述べる。簡単な例をだすと、グレイスケール(階調をもった白黒画像)における色の濃淡は白と黒の密度によって表現できると言える。つまり、濃度が波を繰り返される回数(周波数)に変換できる。これに対してカラー画像は濃淡が二次元的に変化する。静止画像は、どのような周波数の色がどんな濃淡で含まれるかで表わせる。つまり、一般に画像は「どのような周波数がどれくらい含まれているか」によって表現する事ができる。DCTでは、初めに周波数成分を正弦波に分割する。
次に、正弦波について説明する。振幅と波長がそれぞれ一定で規則正しい波は“正弦波”と呼ばれ、x,y 軸をとった場合、y=cos(x), y=cos(2x), y=cos(3x), …で表わされる。ちなみにy=cos(2x) は、y=cos(x) をx軸方向に2倍縮めた正弦波である。DCTではどんな成分でもこの正弦波の組み合わせで近似的に表現が可能であるという事を利用している。分かりやすく、白黒の静止画像で考えると、この“波の山”に近づく程、白に近づき、又“波の谷”に近づく程、黒になるといった決まり事を決めて周波数成分に変換して波にする。このような任意の周波数の曲線を複数の正弦波に分解して係数化する事をDCT演算と呼ぶ。
係数化とは、各静止画像を分割したブロックに対して、DCT演算を行い、周波数成分の大きさ(振幅)を係数として、符号化する事である。尚、画像復元時には、DCT演算と全く逆の演算と施す。DCT演算で使う係数をそのまま符号化しただけでも情報量は減るが、実際のJPEG / MPEG方式では、人間には分からない成分を省略し、単純なDCT係数にして更に圧縮している。
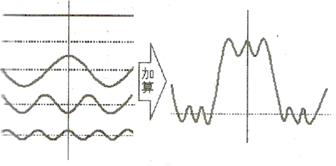
図1.2-b : 正弦波による波表現のイメージ図
1.3 動画圧縮の概要
ここでは、大きく分類した際、予測符号化に当たるフレーム間予測、動き補償予測について説明し、動画圧縮の概要とする。
静止画・動画は、ともに人間の目に不自然に見えなければ、完全に復元する事はできなくても良い。この事を利用して、高い圧縮率が実現されている。
また、標準的な動画は、1フレームあたり30フレームである。したがって、連続する2フレーム間ではおよそ33ミリ秒しか時間経過しかないので、ほとんど動かない。つまり、連続した画像の差分をとって、符号化すれば圧縮できる。これをフレーム間予測符号化(図1-3-b)という。
しかし、画像の中で静止している部分が多ければフレーム間予測は有効だが、そうでない場合の圧縮率は低くなる。その為、動き補償予測(図1-3-c)と呼ばれる動画圧縮方法が考えられた。それは被写体が動いている領域の情報量を削減する方法である。現フレームでの被写体の領域を符号化する時は、前フレームの画像のうち、動いた距離だけシフトした領域の画素値を用いて差をとる。そうする事によって、差分値の統計的偏りを大きくする。ただ、この方法では差分値の他に動いた距離を表わす情報も伝達する必要があるが、全体としての情報量が少なくなればいい。
動画圧縮では、前述の圧縮アルゴリズムを適用する前に1.2で述べたDCT符号化圧縮を行う。そして、この章で述べた動画圧縮を行い更に、1.1で述べたエントロピー符号化を行っている。
したがって、動画像の圧縮方式(MPEG)は、モデムに使われている物理学を基礎とするDCT演算、動画像圧縮特有の予測誤差を求める方法、テキストデータやプログラムの圧縮時に使われているエントロピー圧縮というように、色々な分野の圧縮技術の集大成であると言える。
以下、この章で取り上げた動画圧縮方法を適用した図を示す。各セルの値は、色の値と考えても差し支えない。太線は被写体の輪郭である。
図1.3-a : サンプル動画(2フレーム)
|
50 |
50 |
50 |
50 |
50 |
50 |
|
50 |
50 |
50 |
55 |
50 |
50 |
|
50 |
50 |
55 |
56 |
55 |
50 |
|
50 |
50 |
55 |
56 |
55 |
50 |
|
50 |
50 |
55 |
56 |
55 |
50 |
|
50 |
50 |
55 |
56 |
55 |
50 |
(A)現フレームの画像
|
50 |
50 |
50 |
50 |
50 |
50 |
|
50 |
50 |
55 |
50 |
50 |
50 |
|
50 |
55 |
56 |
55 |
50 |
50 |
|
50 |
55 |
56 |
55 |
50 |
50 |
|
50 |
55 |
56 |
55 |
50 |
50 |
|
50 |
55 |
56 |
55 |
50 |
50 |
(B)前フレームの画像
図1.3-b : フレーム間予測符号化
|
50 |
50 |
50 |
50 |
50 |
50 |
|
50 |
50 |
-5 |
5 |
50 |
50 |
|
50 |
-5 |
-1 |
1 |
5 |
50 |
|
50 |
-5 |
-1 |
1 |
5 |
50 |
|
50 |
-5 |
-1 |
1 |
5 |
50 |
|
50 |
-5 |
-1 |
1 |
5 |
50 |
(C)フレーム間予測誤差
図1.3-c : 動き予測符号化
|
50 |
50 |
50 |
50 |
50 |
50 |
|
50 |
50 |
50 |
55 |
50 |
50 |
|
50 |
50 |
55 |
56 |
55 |
50 |
|
50 |
50 |
55 |
56 |
55 |
50 |
|
50 |
50 |
55 |
56 |
55 |
50 |
|
50 |
50 |
55 |
56 |
55 |
50 |
(D)被写体が「右に1画素」シフトした画像
|
0 |
0 |
0 |
0 |
0 |
0 |
|
0 |
0 |
-5 |
0 |
0 |
0 |
|
0 |
-5 |
0 |
0 |
0 |
0 |
|
0 |
-5 |
0 |
0 |
0 |
0 |
|
0 |
-5 |
0 |
0 |
0 |
0 |
|
0 |
-5 |
0 |
0 |
0 |
0 |
(E)動き補償予測誤差
1.4 圧縮符号化のまとめ
ランレングス符号化は、データベースを圧縮すると、効果を発揮するそうだ。なぜなら、固定長のデータに、何も入っていない場合、スペースが固定長分、続くからだという。
私は、前述の符号化よりハフマン符号化の方が汎用的な圧縮符号化であると考え、符号化表を作成するという負担を加味しても有効な圧縮が行われると考える。
DCPMは、上と左の画素の差分をとって情報量を減らしているというのは、前述の通りである。DCPMを使ったJPEGは濃淡差の少ないイラストデータの圧縮は他の画像圧縮方式に対して不利であると言われている。しかし、私の経験ではそのような画像でもJPEGでもかなりの圧縮率が期待できる。よって、JPEGで圧縮しておけば、問題は少ないと思われる。
DCTで使う理論は、通信でアナログ・デジタル双方向変換する時に使う、モデムの変調方式に類似していると考えられる。このように違った分野の良い技術を取り入れる事は、重要であると考える。
フレーム間予測符号化は、原理は安易に思いつくが、これを実現するには、様々な知識が必要である。これからは、もっと高度な「予測」ができ圧縮率は高まるであろう。